Kafka(一)基础特性
linkin的开源消息队列,现在随着大数据一起非常火。但是并不是只能用于大数据那一套上,可以说是一个基础的组件,用处非常广。特点是持久化快,吞吐量大。 与Nosql数据库相对关系型数据库设计一样,设计上去除了很多束缚,解决特定领域(需要持久化快,吞吐量大)的问题。例如所有消息都会持久化,pull的消息方式,只保证同一partition的消息顺序等。
使用场景
- Messaging 当消息队列用
- Website Activity Tracking 用户行为记录
- Metrics监控用,java中也有meterics工具
- Log Aggregation日志聚合,作为一个日志中心使用
- Stream Processing 流处理,与spark streaming类似
- Event Sourcing 有点抽象,事件流驱动
- Commit Log 功能类似数据库的日志,可以顺序恢复操作或消息
Feature
持久化快
顺序写磁盘,与随机写内存差不多。7200转的硬盘有100MB的速度,一般固态有300MB速度,更快固态硬盘的有500MB的速度
高吞吐率,写,读都有负载均衡
在发送一条消息时,可以指定这条消息的key,Producer根据这个key和Partition机制来判断应该将这条消息发送到哪个Parition。
同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
简化设计
- pull简化broker设计
- 只保证partition内顺序
- Producer和Consumer只与是Leader的partition交互,其它Replica作为Follower从Leader中复制数据.如果没有一个Leader,所有Replica都可同时读/写数据,那就需要保证多个Replica之间互相(N×N条通路)同步数据,数据的一致性和有序性非常难保证
使用zk
- 记录topic
- 记录consumer,录Consumer在该Partition中读取的消息的offset
delivery guarantee
producer到broker
Producer在发布消息到某个Partition时,先通过Zookeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。
可通过配置request.required.acks改变提交的可靠性
broker到consumer处理有三种方式
- 自动commit
- 读完马上commit
- 读完,处理完才commit
不处理Byzantine问题
拓扑结构
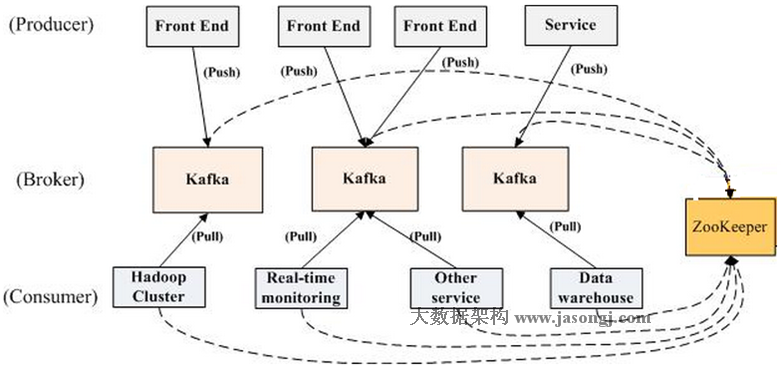
一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
High Availability
为何需要Leader Election
如果没有一个Leader,所有Replica都可同时读/写数据,那就需要保证多个Replica之间互相(N×N条通路)同步数据,数据的一致性和有序性非常难保证 Leader负责数据读写,Follower只向Leader顺序Fetch数据(N条通路),系统更加简单且高效。
MYQA
Q: 目前公司使用大数据的方式是在中心收集到数据后调用提供的sdk,发送到他们的kafka上大数据平台处理,这种方式问题? A: 既然有了kafka,应该算一个底层的支持,数据应该直接到kafka,应用服务器的中心与大数据平台订阅方式获取数据。
Q: why kafka is pull based instead of push based?
- a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred.需要处理各种慢consumer,consumer重启等问题
- Another advantage of a pull-based system is that it lends itself to aggressive batching of data sent to the consumer.
- 实际中,push的方式,如果是顺序发送也会有一定的batch如果是来一个消息立刻上报,那么会浪费很多系统调用
- allow the consumer request to block in a “long poll” waiting until data arrives (and optionally waiting until a given number of bytes is available to ensure large transfer sizes).
- 能够保证是批量写,kafka特点“大吞吐量”