k8s(一)架构
概述
至于什么是k8s,参考官网的一个描述:
Kubernetes is a portable, extensible open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation.
k8s不仅仅是对容器进行编排,而且对于services也会进行管理。那到底如何使用k8s呢?官网上的:
To work with Kubernetes, you use Kubernetes API objects to describe your cluster’s desired state: what applications or other workloads you want to run, what container images they use, the number of replicas, what network and disk resources you want to make available, and more.
地位与重要性可以用以下一句概括:传统云平台上的“Linux”
一点思考
k8s的与众不同的设计,POD的设计与声明式的理念。
- POD中不仅仅是一个容器,可以是一组相关的容器,POD是调度的最小单位。而且这组容器中可以共享相同的网络与volume,这样设计可以让应用与非功能性的功能解耦,例如日志的收集,可以单独配置相应的收集容器;而且可能在一些场景下需要缓存系统如redis,在一些场景下不需要缓存,可以通过这种方式来现实,而不是从开始就把应用与缓存绑定到一起;此外很多的功能都是通过这种方式来非入侵式地增加功能,如k8s的demonset
- 第二就是k8s的声明式的模型(Declarative model),从本质上,可以把k8s看成一个数据库,所有的通过kuberctl客户端都是通过rest api方式操作数据库,很多controller也是观察数据库进行后续操作。k8s尽可能地保持到所期望的状态:
Provide the “desired state” and Kubernetes will make it happen
天生亲和微服务
由于微服务的存在,根据原子化拆分服务的原则,服务的数目会成百甚至上千,部署的时候,单个物理机上,肯定会部署很多的服务,服务上千,服务器可能几十个或十几个(单个服务器点上可能会有百个服务),如果没有k8s,要人工方式手动编排,工作量是个问题,然后另外一个问题就是如何合理的分配,一是保证各种资源能够平均分配,而是考虑单个或部分服务器节点挂掉的问题,是扩容问题,在以前没有微服务的场景下,服务节点不会很多,一般是一些服务器跑一个服务,场景是10个服务跑在100个机器上(每10个分一组跑一个服务),而到了微服务可能是10000个服务跑在100个机器上,如果在手动编排,那么可能微服务得不偿失。
不仅仅是容器调度,而且有services
如果k8s只是对docker的调度,那么对比spring cloud这套,至少还要有服务的发现、服务的路由、负载均衡这些特性,而这些实现很多都依赖于一些相对固定的IP,但是由于有docker的自由的调度,无法确定,或者说无法绑定容器在哪些IP上(如果提供这种类似k8s label功能实现一些容器绑定在一些固定IP上,系统的可靠性就会有影响),所以相对固定的IP,是与传统的方式一个很重要的区别。
而k8s内部实现了自己的网络,这种方式一般叫软件定义网络。这种把网络层也虚拟化管理起来,方便了云上的管理,网络也是一种资源,与卷存储一样都会有问题,在云里实现网络的灵活控制,才能方便实现各种容器的调度,对资源的分配与利用更加灵活。
对于k8s的使用者来说,容器的自动调度并不是目的,想要的真正价值是通过容器的自动调度实现用户提供服务的自动的容灾、自动根据所需资源进行配置、负载均衡、路由等功能,所以,k8s支持services,合乎逻辑。
架构
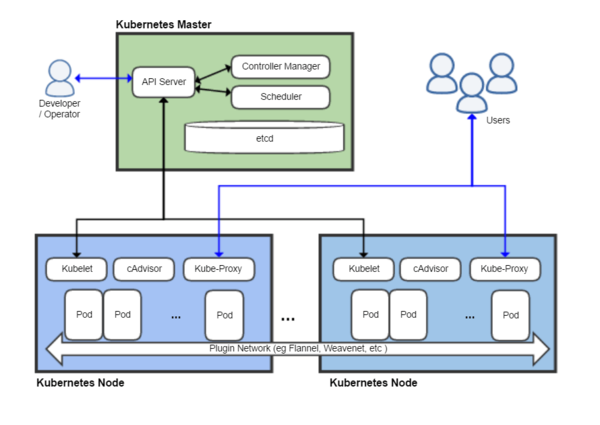
上图是wiki中的一个架构图,图中能表明一下几点:
- 与Hbase、HDFS一样,是有专门的master节点的。但是这个master与Hbase或其他的不一样,并不是给最终的用户用的,而是给开发或运维人员使用
- k8s有自己的数据库
- 使用软件定义的网络,会与以前的传统的网络在使用上有很多不同
典型运行时
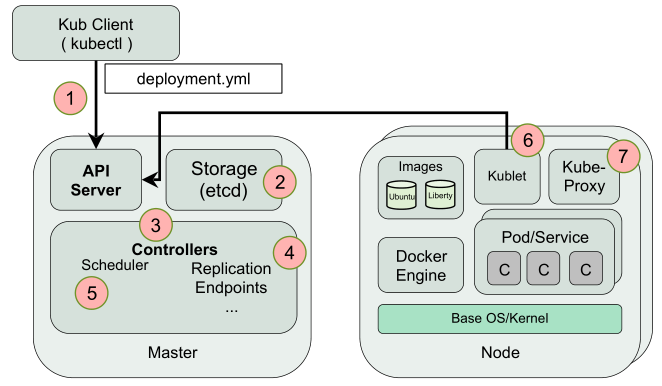
- User via “kubectl” deploys a new application
- API server receives the request and stores it in the DB (etcd)
- Watchers/controllers detect the resource changes and act upon it
- ReplicaSet watcher/controller detects the new app and creates new pods to match the desired # of instances
- Scheduler assigns new pods to a kubelet
- Kubelet detects pods and deploys them via the container runing (e.g. Docker)
- Kubeproxy manages network traffic for the pods – including service discovery and load-balancing
参考的IBM开放课程中的一个架构图。也通过7个步骤简要概括了k8s的一个典型的运行,主要过程体现了k8s的声明式模型。
核心概念
从大的维度看,后者wiki上的那个架构图,k8s套路很普通,分为master与node节点,功能么与其他分布式系统的职责分配也差不多,master负责控制、调度、集群配置,而node节点也叫worker,就是负责干活的。
k8s中有Object的概念:
Kubernetes Objects are persistent entities in the Kubernetes system. Kubernetes uses these entities to represent the state of your cluster. Specifically, they can describe:
- What containerized applications are running (and on which nodes)
- The resources available to those applications
- The policies around how those applications behave, such as restart policies, upgrades, and fault-tolerance
常见的包括:POD、Service、Volume、Namespace。
另外一个常见概念是controller:
Controllers build upon the basic objects, and provide additional functionality and convenience features.
Master Components
Master components provide the cluster’s control plane. Master components make global decisions about the cluster (for example, scheduling), and detecting and responding to cluster events (starting up a new pod when a replication controller’s ‘replicas’ field is unsatisfied).
与HBase或HDFS的master一样,负责控制、调度和整个集群的配置。而且都是建议单独部署,并考虑高可用。由kube-apiserver、etcd、kube-scheduler、kube-controller-manager、cloud-controller-manager组成。
什么是“cotrol plane”?
是这个概念是网络设备中的一个概念,参考:Difference between control plane, data plane and management plane?
These terms are abstract logical concepts, much like the OSI model.
Data plane refers to all the functions and processes that forward packets/frames from one interface to another.
Control plane refers to all the functions and processes that determine which path to use. Routing protocols, spanning tree, ldp, etc are examples.
Management plane is all the functions you use to control and monitor devices.
These are mostly logical concepts but things like SDN separate them into actual devices.
Finally, all manufacturers use these concepts.
为什么要扯出这些平面的概念?
假设这几个平面不进行任何的分离,数据平面和控制、管理平面使用共用的主机资源,在大数据流量、复杂应用环境下数据平面由于承担着繁重的日常任务将可能消耗绝大部分资源,这对于整个交换机系统无疑是灾难性的,因为在某些极端的情况下,控制平面将没有充分的资源来保障运行,这就意味网络设备失去了对设备所处网络环境的真实了解,网络设备将立即陷于非正常工作状态甚至瘫痪状态,而管理人员也没有资源使用管理平面对网络设备的运行进行干预,所以数据平面需要严格地与控制平面、管理平面进行分离。
最重要的是资源隔离,由于不同的功能的重要性不同,对所需资源的要求不同(有的需求大但可靠性不高,有的需求小,但对可靠性要求非常搞),需要对不同的功能进行分类、分级,就出来了上面几个概念。
例如,上面提到的几个系统,不论是k8s还是hbase,都有单独的master node和一般的work node,没有做成无中心控制的方式一是太复杂,二是对可靠性的要求,master节点本来没有很多对资源的要求(cpu,io)等,只是对可靠性有要求。如果设计成无中心的方式,虽然通过各种一致性的协议,一些选举的特性也可以完成,但是对于设计的复杂性、运维的复杂性,达到同样稳定性对资源的要求需要花费的成本会很高。
kube-scheduler
Component on the master that watches newly created pods that have no node assigned, and selects a node for them to run on.
POD是最小的资源调度单位,这个kube-scheduler也理所当然是调度的POD。
kube-controller-manager
Component on the master that runs controllers .
Logically, each controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process.
These controllers include:
- Node Controller: Responsible for noticing and responding when nodes go down.
- Replication Controller: Responsible for maintaining the correct number of pods for every replication controller object in the system.
- Endpoints Controller: Populates the Endpoints object (that is, joins Services & Pods).
- Service Account & Token Controllers: Create default accounts and API access tokens for new namespaces
controller-manager管理的是很多种controller。感觉上面的scheduler也像一种controller,但是考虑其重要的功能,对核心的POD进行管理,为显示重要性,单独出来,而且scheduler是能够替换的,也就是说能自定义scheduler算法。但这感觉和负载均衡算法一样,就那么几种,发挥的空间不是很大。
从上面的意思看,manager的是管理controller的,manager是真正的管理者,而controller是基层管理做一些具体的事情。软件上,manager的一般是对所有的资源的多种功能的控制和访问,提供一个统一的入口。
常用命令
- kubectl get - list resources
- kubectl describe - show detailed information about a resource
- kubectl logs - print the logs from a container in a pod
- kubectl exec - execute a command on a container in a pod
部署一个deployment的命令:
kubectl run kubernetes-bootcamp –image=gcr.io/google-samples/kubernetes-bootcamp:v1 –port=8080
启动services的命令:
kubectl expose deployment/kubernetes-bootcamp –type=”NodePort” –port 8080
另外services的四种类型:
- ClusterIP (default) - Exposes the Service on an internal IP in the cluster. This type makes the Service only reachable from within the cluster.
- NodePort - Exposes the Service on the same port of each selected Node in the cluster using NAT. Makes a Service accessible from outside the cluster using
: . Superset of ClusterIP. - LoadBalancer - Creates an external load balancer in the current cloud (if supported) and assigns a fixed, external IP to the Service. Superset of NodePort.
- ExternalName - Exposes the Service using an arbitrary name (specified by externalName in the spec) by returning a CNAME record with the name. No proxy is used. This type requires v1.7 or higher of kube-dns.
第一种ClusterIP方式应该是不对外提供服务的,内部的微服务的方式,后面三种是对外提供服务的方式;
第二种NodePort可以很多的Node提供相同的port,这种方式,理论上是比第三种LoadBalancer这种方式能够支持的流量更大,不受单网卡带宽、单节点的CPU限制,入口点不是唯一的。但这方式对内部系统提供服务,需要系统知道集群的ip,对外(互联网)意义不是很大,因为入口点为一个,而且就像名字一样,没有第三种类型的负载均衡的功能; 而ExternalName的方式,都不用前端做路由的Nginx,可以直接提供类似通过域名方式访问服务。
删除services
kubectl delete service -l run=kubernetes-bootcamp
增加标签:
kubectl label pod $POD_NAME app=v1
给一个deployment扩容
kubectl scale deployments/kubernetes-bootcamp –replicas=4
升级image版本
kubectl set image deployments/kubernetes-bootcamp kubernetes-bootcamp=jocatalin/kubernetes-bootcamp:v2
image回滚
kubectl rollout status deployments/kubernetes-bootcamp kubectl rollout undo deployments/kubernetes-bootcamp