ceph体系结构
接触后第一感觉是,智能且复杂。功能考虑全面,支持块存储、文件存储、对象存储,从基本的集群要求的自动恢复、高可靠性到最底层的支持自己磁盘文件系统,各种功能基本都考虑到了。简单总结下特点:
- 无中心节点问题,支持无限扩展,设计之初就是面向的PB级的数据量。说明有中心节点,是没有一般像Hbase、Kafka依赖ZK这样的访问前查询的节点,没有类似HDFS的namenode节点,对元数据的大小并不敏感,文件再多,也不会飙升大量的内存用于文件的路由查询。那怎么知道去哪里写哪里读呢——直接用crush算法计算出来。
- 支持超大规模。与上面一点很有关系,在PB和EB级别,调度系统是整个系统的瓶颈,采用计算文件地址而不是查询文件地址的方式,客户端与OSD都能感知集群等方式,解决了调度系统的瓶颈问题。
- 高可用监视器。虽然无中心节点,但是有监视器存储着集群运行图,可以理解为集群的元数据,这监视器如果都不能用的话客户端也不能用。一致性问题么,与zk一样使用了更复杂的paxos算法。
- 自动恢复,自愈的。虽然各个分布式文件系统都有类似的功能,有的比较简单像fastdfs只是group内的自动相互备份,是整个storage服务器数据迁移,在group一台挂掉的情况下,另外的可能形成热点,如果运维不及时,再出现问题很可能造成数据丢失(一份数据只在group内备份),苛刻点讲fastdfs并没有自愈的功能。而kafka是以partition为单位进行存储,数据块小,相对fastdfs而言分布的更加均匀。ceph采用的crush算法,虽然不是很懂,但是作为一个以智能自居的系统,处理这点failover上还是没问题的。
- 支持重均衡。在加入一台设备后,会立刻均衡使用此设备,减缓以前设备的压力。
- 有缓存机制,缓存分级。对付热点问题的银弹,对于PB级的存储系统,缓存不只是内存的形式,可以配置SSD和机械硬盘组合的方式,然后ceph会智能的充分地使用速度更快SSD,掏空你的CPU、内存与磁盘IO。
- 支持文件存储、快存储、对象存储。虽然这特征比较明显,但感觉用处不大。文件存储还不稳定,快存储貌似已经是开源的一哥,对象存储也用的很广泛。
- 支持条带化,像RAID一样。有更高的写入速度。
- 自动文件清洗,检查文件磁盘错误自动恢复。
- 有纠删编码机制,在PB级的系统中,文件损坏是日常,而不是异常。很多时候下载都有个md5的验证,那验证错了怎么办?只能重新下载。而ceph是数据源,不能轻易丢掉数据,可以利用纠错编码的机制恢复错误的数据。有了编码的机制,虽然只存了三份数据,但是还有两份编码(体积相对小),可以相当于五份数据的存储。提高了数据的可靠性,节省了存储空间(与五份原始数据比),当然,浪费了点cpu,不是浪费是充分利用了cpu。
更加详细的介绍参考体系结构 ,非常的详细。
下面简单介绍下三张图:
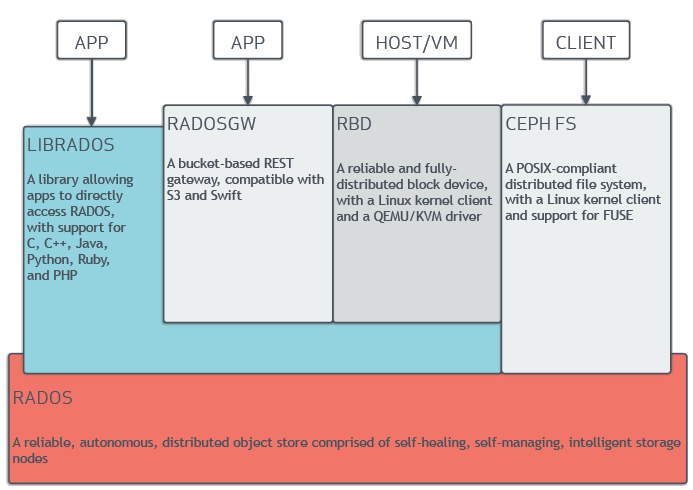
上图能看到,所有的一切都是RADOS(reliable autonomous distribute object system),而上面是对文件存储、块存储、文件存储的封装。

上图中,有了三个基本概念,obj对象,PG归置组,OSD(Object storage device)OSD。其中PG中间这一层是为了隔离变化。
把对象映射到归置组在 OSD 和客户端间创建了一个间接层。由于 Ceph 集群必须能增大或缩小、并动态地重均衡。如果让客户端“知道”哪个 OSD 有哪个对象,就会导致客户端和 OSD 紧耦合;相反, CRUSH 算法把对象映射到归置组、然后再把各归置组映射到一或多个 OSD ,这一间接层可以让 Ceph 在 OSD 守护进程和底层设备上线时动态地重均衡。

上图也是看ceph的一个维度,包括了客户端,协议,底层运行的逻辑节点,一般运行中有多个OSD,Monitor,和多个MDS元数据服务器(在对象存储中不需要)。
下面是整理的一些,直接引用的官方文档上的:
Ceph 监视器维护着集群运行图的主副本。一个监视器集群确保了当某个监视器失效时的高可用性。存储集群客户端向 Ceph 监视器索取集群运行图的最新副本。
Ceph OSD 守护进程检查自身状态、以及其它 OSD 的状态,并报告给监视器们。
存储集群的客户端和各个 Ceph OSD 守护进程使用 CRUSH 算法高效地计算数据位置,而不是依赖于一个中心化的查询表。
Ceph 存储集群从 Ceph 客户端接收数据——不管是来自 Ceph 块设备、 Ceph 对象存储、 Ceph 文件系统、还是基于 librados 的自定义实现——并存储为对象。每个对象是文件系统中的一个文件,它们存储在对象存储设备上。由 Ceph OSD 守护进程处理存储设备上的读/写操作
数据的存储 Ceph OSD 在扁平的命名空间内把所有数据存储为对象(也就是没有目录层次)。对象包含一个标识符、二进制数据、和由名字/值对组成的元数据,元数据语义完全取决于 Ceph 客户端。例如, CephFS 用元数据存储文件属性,如文件所有者、创建日期、最后修改日期等等。一个对象 ID 不止在本地唯一 ,它在整个集群内都是唯一的。
伸缩性和高可用性
在传统架构里,客户端与一个中心化的组件通信(如网关、中间件、 API 、前端等等),它作为一个复杂子系统的唯一入口,它引入单故障点的同时,也限制了性能和伸缩性(就是说如果中心化组件挂了,整个系统就挂了)。
Ceph 消除了集中网关,允许客户端直接和 Ceph OSD 守护进程通讯。 Ceph OSD 守护进程自动在其它 Ceph 节点上创建对象副本来确保数据安全和高可用性;为保证高可用性,监视器也实现了集群化。为消除中心节点, Ceph 使用了 CRUSH 算法。
在很多集群架构中,集群成员的主要目的就是让集中式接口知道它能访问哪些节点,然后此中央接口通过一个两级调度为客户端提供服务,在 PB 到 EB 级系统中这个调度系统必将成为最大的瓶颈。
Ceph 消除了此瓶颈:其 OSD 守护进程和客户端都能感知集群,比如 Ceph 客户端、各 OSD 守护进程都知道集群内其他的 OSD 守护进程,这样 OSD 就能直接和其它 OSD 守护进程和监视器通讯。另外, Ceph 客户端也能直接和 OSD 守护进程交互。
Ceph 客户端和 OSD 守护进程都用 CRUSH 算法来计算对象的位置信息,而不是依赖于一个中心化的查询表。与以往方法相比, CRUSH 的数据管理机制更好,它很干脆地把工作分配给集群内的所有客户端和 OSD 来处理,因此具有极大的伸缩性。 CRUSH 用智能数据复制确保弹性,更能适应超大规模存储。
Ceph 的关键设计是自治,自修复、智能的 OSD 守护进程。
每个存储池都有很多归置组, CRUSH 动态的把它们映射到 OSD 。 Ceph 客户端要存对象时, CRUSH 将把各对象映射到某个归置组。
Ceph 客户端绑定到某监视器时,会索取最新的集群运行图副本,有了此图,客户端就能知道集群内的所有监视器、 OSD 、和元数据服务器。然而它对对象的位置一无所知。 对象位置是计算出来的。
Ceph 存储集群被设计为至少存储两份对象数据(即 size = 2 ),这是保证数据安全的最小要求。
主 OSD 是 acting set 中的第一个 OSD ,而且它负责协调以它为主 OSD 的各归置组 的互联,也只有它会接受客户端到某归置组内对象的写入请求。 PS:写的时候设计都一样,通过主一个节点来写,与fastdfs,kafka一样。
作为维护数据一致和清洁的一部分, OSD 也能清洗归置组内的对象,也就是说, OSD 会比较归置组内位于不同 OSD 的各对象副本的元数据。清洗(通常每天执行)是为捕获 OSD 缺陷和文件系统错误, OSD 也能执行深度清洗:按位比较对象内的数据;深度清洗(通常每周执行)是为捕捉那些在轻度清洗过程中未能发现的磁盘上的坏扇区。
对于后端存储层上的部分热点数据,缓存层能向 Ceph 客户端提供更好的 IO 性能。缓存分层包含由相对高速、昂贵的存储设备(如固态硬盘)创建的存储池,并配置为 缓存层;以及一个后端存储池,可以用纠删码编码的或者相对低速、便宜的设备,作为经济存储层。 Ceph 对象管理器会决定往哪里放置对象,分层代理决定何时把缓存层的对象刷回后端存储层。所以缓存层和后端存储层对 Ceph 客户端来说是完全透明的。
存储设备都有吞吐量限制,它会影响性能和伸缩性,所以存储系统一般都支持条带化(把连续的信息分片存储于多个设备)以增加吞吐量和性能。数据条带化最常见于 RAID 中, RAID 中最接近 Ceph 条带化方式的是 RAID 0 、或者条带卷, Ceph 的条带化提供了像 RAID 0 一样的吞吐量、像 N 路 RAID 镜像一样的可靠性、和更快的恢复。
S3/Swift 对象和存储集群对象比较 Ceph 对象存储用对象这个术语来描述它存储的数据。 S3 和 Swift 对象不同于 Ceph 写入存储集群的对象, Ceph 对象存储系统内的对象可以映射到 Ceph 存储集群内的对象; S3 和 Swift 对象却不一定 1:1 地映射到存储集群内的对象,它有可能映射到了多个 Ceph 对象。