DDD
概念
Domain-driven design (DDD) is the concept that the structure and language of your code (class names, class methods, class variables) should match the business domain. For example, if your software processes loan applications, it might have classes such as LoanApplication and Customer, and methods such as AcceptOffer and Withdraw.
统一语言后,code中的命名、操作方法名与业务领域的名字保持一致,也就是说业务专家可能决定领域对象的code中的命名,命名也是一种语言的统一,一个词一个意思。
最关键的是,如何找到这core domain,如何去划分聚合根、界限上下文。
DDD connects the implementation to an evolving model.[1]
Domain-driven design is predicated on the following goals:
- placing the project’s primary focus on the core domain and domain logic;
- basing complex designs on a model of the domain;
- initiating a creative collaboration between technical and domain experts to iteratively refine a conceptual model that addresses particular domain problems.
项目主要精力集中在核心领域和领域逻辑上。如果说查询不是业务,那么核心逻辑应该是核心领域对象的状态流转。其实与开发代码有些类似,如果从性能角度看,更要注重hot path,是性能优化中的关键点。
DDD领域建模优先,领域建模的时基本不考虑数据模型和数据库实现。在微服务具体落地的时候才考虑数据实体的设计。
界限上下文(bounded context)
通过英文翻译比较容易理解,有边界的上下文。一般的,像spring中的上下文基本是一个包括所有信息的上下文,而这里更强调边界,每个上下文都有自己的边界,这样才能让业务领域的概念明确,并且相对简单。
如果不划分边界,比如商品这个概念,在审核阶段有自己的审核状态、审核人员、审核的过程的一些标识等,在上线后,有下载数量、订单数量等信息,通过客户端打点,商品还有有自己的曝光、点击、订单率等统计信息。如果没有一个明确的边界,那么商品这个概念就非常的大,大家可能不知道表达的重点是什么。通用语言必须与限界上下文配合使用才有意义。
限界上下文是由若干个聚合构成的,聚合具有一定的业务内聚性。限界上下文,有点类似Java中package或者C++的namespace的概念,在一个命名空间内,一个对象有特定的表达含义。
如果划分边界,那么在不同的边界内,商品的概念就不一样,甚至有自己不同的名字。比如在物流领域可以叫货物,在内容分发领域叫商品。
这样,一个产品的信息就分散到了各个边界内,也就是各个微服务内,如果要查询,并且实时性比较高可能效率就比较低了,比如在设计师站进行查询的时候,这个时候可以考虑对数据进行一些冗余。
还有一种方式,做个数据中台,汇总所有的相关数据,比如统计、审核、运营的标签、基础信息、订单量、营收等,对外给运营、搜索、推荐、设计师提供统一的查询的服务。这样,能减少很多xxx-api的汇总的操作。
子域的划分是一个业务粗分过程。而限界上下文这个设计过程是一个详细的领域建模和微服务设计过程。 如果领域太大,你不方便进行分析和设计。子域划分的主要目的就是为了将领域的问题空间缩小,以方便你下一步进行详细的领域建模和微服务设计,而这个过程是一个非常细致的过程。限界上下文实际上也是一种分析后得出的子域。
界限上下文是从语义的角度进行域的划分的,而子域是从业务的角度进行划分的。
实体
实体一般对应业务对象,它具有业务属性和业务行为;而值对象主要是属性集合,对实体的状态和特征进行描述。
值对象
在领域建模时,我们可以将部分对象设计为值对象,保留对象的业务涵义,同时又减少了实体的数量;在数据建模时,我们可以将值对象嵌入实体,减少实体表的数量,简化数据库设计。 另外,也有 DDD 专家认为,要想发挥对象的威力,就需要优先做领域建模,弱化数据库的作用,只把数据库作为一个保存数据的仓库即可。即使违反数据库设计原则,也不用大惊小怪,只要业务能够顺利运行,就没什么关系。
个人更偏向后者,数据库表本来有表达业务逻辑、高效的存储查询数据两种职责,对于DDD来说有专门的领域模型来表达业务领域的意义、关系,从理论上说,根本不需要在用数据表达业务,所以数据库设计只想着存储应该就ok了。
但如果是贫血模型,事务脚本的方式,因为没有专门的表达业务的领域对象,那么不得不去精心维护数据库表,在业务领域变化的时候,去该表表之间的关系。
值对象采用序列化大对象的方法简化了数据库设计,减少了实体表的数量,可以简单、清晰地表达业务概念。这种设计方式虽然降低了数据库设计的复杂度,但却无法满足基于值对象的快速查询,会导致搜索值对象属性值变得异常困难。
有些场景比如主题的截图信息,会有多张图片,而且不会有基于单张图片的搜索,这个时候就可以通过序列化大对象的方法简化数据库的设计,把所有的截图信息序列化为json存储在数据库中。
同样的对象在不同的场景下,可能会设计出不同的结果。有些场景中,地址会被某一实体引用,它只承担描述实体的作用,并且它的值只能整体替换,这时候你就可以将地址设计为值对象,比如收货地址。而在某些业务场景中,地址会被经常修改,地址是作为一个独立对象存在的,这时候它应该设计为实体,比如行政区划中的地址信息维护。
更加印证了上面一点,截图信息就是这种被整体替换的的对象,没有必要再去分别存储。
DDD 引入值对象还有一个重要的原因,就是到底领域建模优先还是数据建模优先?DDD 提倡从领域模型设计出发,而不是先设计数据模型。前面讲过了,传统的数据模型设计通常是一个表对应一个实体,一个主表关联多个从表,当实体表太多的时候就很容易陷入无穷无尽的复杂的数据库设计,领域模型就很容易被数据模型绑架
这也是设计思路的一个转化。在互联网的业务表设计中很多出于查询的考虑对数据进行了冗余,丢失或者说模糊了一部分数据模型的意图,如果这个时候业务更加复杂,又是贫血模型,就可能从代码、从表中在找到本来的业务设计意图。
聚合
领域模型内的实体和值对象就好比个体,而能让实体和值对象协同工作的组织就是聚合,它用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性。
聚合就是由业务和逻辑紧密关联的实体和值对象组合而成的,聚合是数据修改和持久化的基本单元,每一个聚合对应一个仓储,实现数据的持久化。
聚合在 DDD 分层架构里属于领域层,领域层包含了多个聚合,共同实现核心业务逻辑。聚合内实体以充血模型实现个体业务能力,以及业务逻辑的高内聚。跨多个实体的业务逻辑通过领域服务来实现,跨多个聚合的业务逻辑通过应用服务来实现。比如有的业务场景需要同一个聚合的 A 和 B 两个实体来共同完成,我们就可以将这段业务逻辑用领域服务来实现;而有的业务逻辑需要聚合 C 和聚合 D 中的两个服务共同完成,这时你就可以用应用服务来组合这两个服务。
领域服务,比如对A账户扣款,对于B账户付款,不好定义一个实体来包装这个行为,这个时候就需要领域服务来进行协调。
聚合根
如果把聚合比作组织,那聚合根就是这个组织的负责人。聚合根也称为根实体,它不仅是实体,还是聚合的管理者。
首先它作为实体本身,拥有实体的属性和业务行为,实现自身的业务逻辑。 其次它作为聚合的管理者,在聚合内部负责协调实体和值对象按照固定的业务规则协同完成共同的业务逻辑。 最后在聚合之间,它还是聚合对外的接口人,以聚合根 ID 关联的方式接受外部任务和请求,在上下文内实现聚合之间的业务协同
这聚合根有些类似业务网关,有一部分自己的职责(加解密、认证),协调聚合(能够调度下面的service完成复杂的功能),又是个接口人决定什么是暴露出去的(典型的网关职责)。这有些像在业务领域的网关,网关可以理解为架构领域的。
领域事件
聚合的一个设计原则:在边界之外使用最终一致性。一次事务最多只能更改一个聚合的状态。如果一次业务操作涉及多个聚合状态的更改,应采用领域事件的最终一致性。 领域事件驱动设计可以切断领域模型之间的强依赖关系,事件发布完成后,发布方不必关心后续订阅方事件处理是否成功,这样可以实现领域模型的解耦,维护领域模型的独立性和数据的一致性。在领域模型映射到微服务系统架构时,领域事件可以解耦微服务,微服务之间的数据不必要求强一致性,而是基于事件的最终一致性。
消息驱动的方式也是解耦合,领域事件是从业务领域的角度的划分的概念,消息驱动可以理解为是架构方便的划分。而且领域事件应用场景也是有条件,一般只用于解耦微服务。
但在上面也提到,聚合的概念虽然一个微服务内有多个聚合,但后续聚合就是拆分微服务的根据,所以,如果考虑后续扩展,在微服务内使用领域事件的方式,只不过不用非要通过MQ的方式,通过spring event的方式可以前期快速实现。拆分的时候在转换成MQ的方式。还有,即使使用spring event的方式,还是会有复杂度的问题,在获得的收益与复杂度上可能需要看场景。
事件发布之前需要先构建事件实体并持久化。事件发布的方式有很多种,你可以通过应用服务或者领域服务发布到事件总线或者消息中间件,也可以从事件表中利用定时程序或数据库日志捕获技术获取增量事件数据,发布到消息中间件。
持久化的主要原因是为了对账,回溯,还有就是可以增加一部分审计的功能。从另外一个角度,不同微服务之间可能是不同组的人员维护,可以理解为一个“外部系统”,就向打日志规范一样,一般外部系统的调用出参和入参还都需要记录。一般是持久化到本地数据库的事件表中如果持久化到一个外部的库可能有分布式事务的问题。
通过上面的分析,DDD并不是要极力推崇事件驱动的架构,领域事件是服务与服务之间的,这就决定了事件不会很多。而且服务之间的领域事件的发送、接收都需要持久化,对领域事件的应用也产生了成本。
架构模型
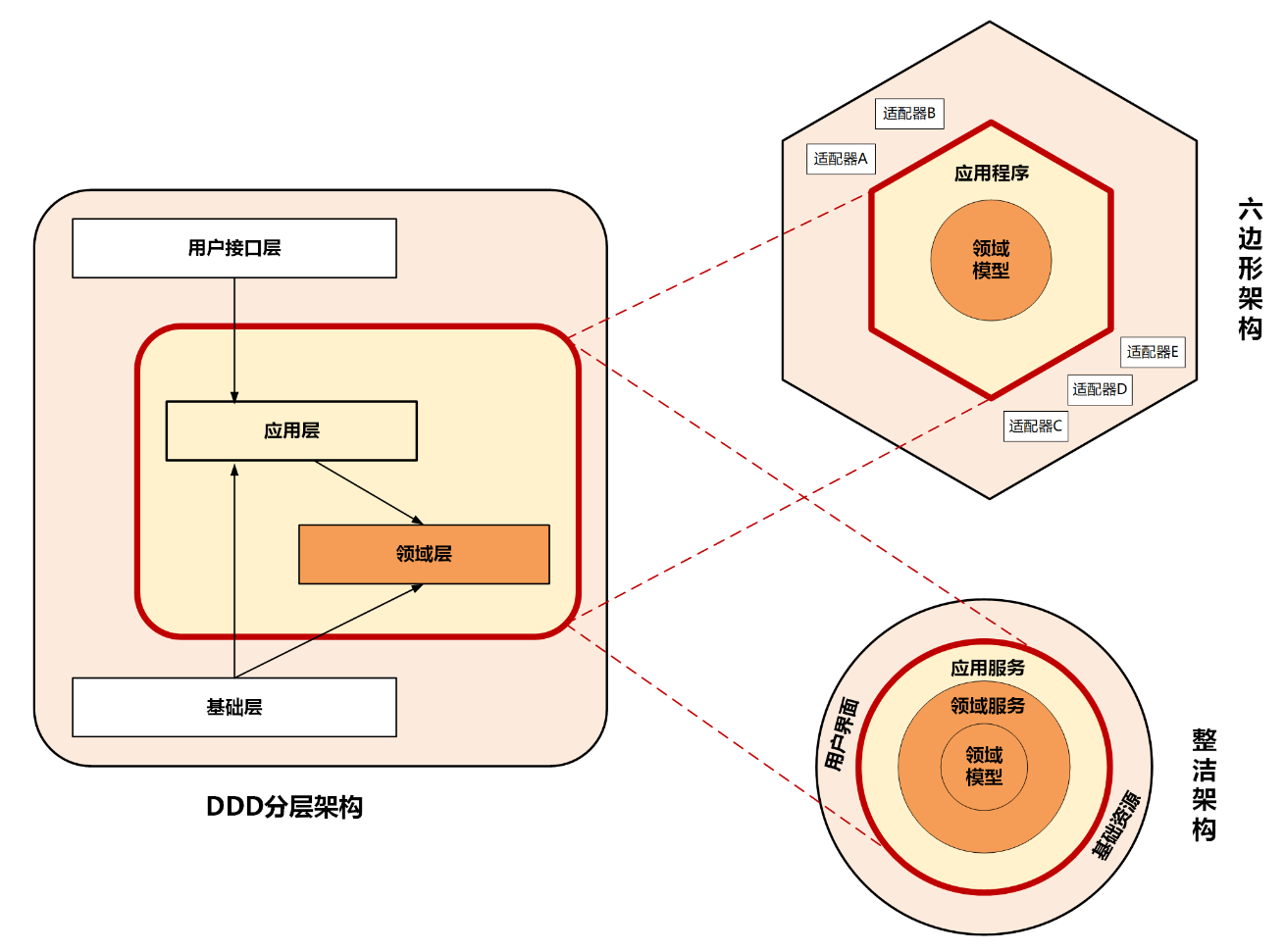
整洁架构最主要的原则是依赖原则,它定义了各层的依赖关系,越往里依赖越低,代码级别越高,越是核心能力。外圆代码依赖只能指向内圆,内圆不需要知道外圆的任何情况。
六边形架构的核心理念是:应用是通过端口与外部进行交互的。我想这也是微服务架构下 API 网关盛行的主要原因吧。也就是说,在下图的六边形架构中,红圈内的核心业务逻辑(应用程序和领域模型)与外部资源(包括 APP、Web 应用以及数据库资源等)完全隔离,仅通过适配器进行交互。它解决了业务逻辑与用户界面的代码交错问题,很好地实现了前后端分离
DDD的分层架构于与整洁架构与六边形最重要的是分层架构能够跃层访问,可分层的架构如下:
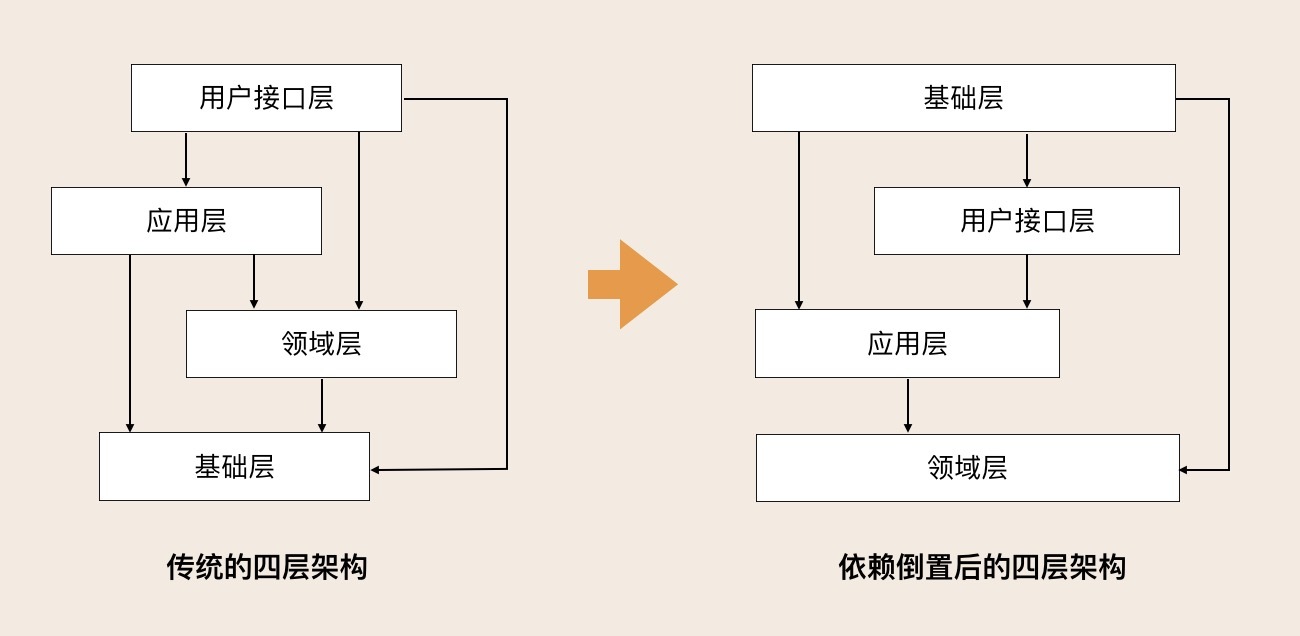
这种能够跃层访问的优势就是灵活,比如一些查询操作,可以直接去访问仓储库,而不用经过领域对象,这样让领域实体或聚合更加清晰。
这三种架构都考虑了前端需求的变与领域模型的不变。需求变幻无穷,但变化总是有矩可循的,用户体验、操作习惯、市场环境以及管理流程的变化,往往会导致界面逻辑和流程的多变。但总体来说,不管前端如何变化,在企业没有大的变革的情况下,核心领域逻辑基本不会大变,所以领域模型相对稳定,而用例和流程则会随着外部应用需求而随时调整。
这说法似曾相识,在微服务的架构下,各个service提供基础的服务,然后通过一个聚合服务api服务对服务进行编排暴露,在业务需求变化的时候修改聚合服务。
领域建模
事件风暴
在DDD的实践中,战略设计比战术设计更重要,划分边界,划分职责,是保证后续服务高内聚的重要条件。
事件风暴的方式是一种自底向上的过程,也是战略设计中经常使用的方法。这个过程是个团队活动,类似头脑风暴。先根据业务流程找出领域中的事件和命令(来自用户或定时任务),在找出命令的角色找出实体。
这种自底向上方式是比较简单和全面的,如果直接找领域中的角色可能会遗漏,因为最直接认知的就是发生的一个个的事件和一个个的业务动态,在实际生活中也是如此。
在找出实体后,根据业务关联性划分聚合,并且从实体中找出聚合根。
最后划分界限上下文,根据语义对聚合进行归类。
在微服务拆分与设计时,我们不能简单地将领域模型作为拆分微服务的唯一标准,它只能作为微服务拆分的一个重要依据。微服务的设计还需要考虑服务的粒度、分层、边界划分、依赖关系和集成关系。除了考虑业务职责单一外,我们还需要考虑将敏态与稳态业务的分离、非功能性需求(如弹性伸缩要求、安全性等要求)、团队组织和沟通效率、软件包大小以及技术异构等非业务因素。
分层主要是从职能上,有些api服务需要单独作为服务,非功能性需求如弹性收缩(活动相关的服务),单接口的性能限制(如打点接口)。
微服务划分可以分为业务和非业务性的需求,业务主要从DDD方面,非业务性可以分为性能方面(伸缩、QPS)、架构分层(网关、api聚合服务)、技术栈异构(是否使用大数据的技术)。
微服务构建
在DDD中如果领域很大的话,内部由小到大的顺序大概是这样的:值对象-》实体-》聚合(最小业务功能单元,如果非常必要可以拆分为微服务)-》限界上下文(一般作为拆分为微服务的依据,包含一到多个聚合)-》子域(包含一到多个限界上下文)-》领域(包含支撑子域、核心子域或通用子域等一到多个子域)。 在有些情况下,一个子域可能就是一个限界上下文,一个限界上下文可能只包含一个聚合。一般来说,在一个限界上下内来构建领域模型,一个领域模型可以设计出一个微服务。 服务的从低向上关系是这样的:实体方法-》领域服务-》应用服务-》Facade接口
背景
- 互联网业务日益负载,接入传统的业务越来越多
- 一般的重构是重构出一个独立的类来放某些通用的逻辑,但是你会发现你很难给它一个业务上的含义,只能给予一个技术维度描绘的含义。如果不是直接拷贝以前的代码逻辑,新同学并不总是知道对通用逻辑的改动或获取来自该类
理解
首先,统一语言,即使不用这DDD的方式,统一语言也是必要的,否则沟通到最后都打成共识了,有可能发现大家对一些概念的理解都不一样。
然后什么是业务?查询,并不是业务。业务的流转才是业务。
业务的分析可以与操作系统结构类比下,操作系统由内到外可以分内核、系统调用、库函数、应用软件,而业务也有自己的的核心-领域模型,对领域模型的对外暴露与封装-领域服务,然后外面为应用服务,最外面,基于应用服务而构建的各种应用。操作系统中,应用程序能够跳过库函数,直接调用系统调用,同样有些类似,外层应用能直接访问领域服务,而不是必须通过应用服务。
由贫血模型,对应的DDD是充血模型,听上去也不是什么好词。有些行为很难界定是属于哪个entity的,所有由了domain service的概念,一些无法放到entity的行为,可以放这里面。比如一个人给另外一个人转账,输入两个entity,在domain service中分别进行操作。
数据驱动开发的问题?
- 很多只能utils层的服用,很多就是一个流程一套代码,从controller到落库。主要原因是没有事先进行抽象,即使有公共的方法,也只能放到一个流程中,但这公共流程放哪里呢?更多的场景是没有想到一个由业务类型的类,最后放到了一个xxUtils的类中
- 没有一个开始的业务模型,在需求增加的时候,新同学可能就会放飞自我,凭着自己的理解甚至感觉对系统进行修改,导致系统的腐败
贫血症会导致失忆症
贫血模型
- 贫血领域对象(Anemic Domain Object)是指仅用作数据载体,而没有行为和动作的领域对象。
- 这是通常web开发中使用的方式,这种方式的优点是开发快,不用提前建模抽象模型,一个流程里面通过get和set对象属性的方式完成。但是会造成失忆症,业务逻辑复杂了,业务逻辑、状态会散落到在大量方法中,原本的代码意图会渐渐不明确,这种情况称为由贫血症引起的失忆症。
- 优点二,如果改动一个流程,为了应对可能的变化,可能并不会刻意抽象出公用的方法,而是在一个流程中重复代码,这样改动时候这个业务与其他业务独立,并不会改变其他的流程,对新人友好。相对的,会造成有部分冗余代码。而使用DDD方式,可能会考虑这个方法是不是模型中重要的行为,增加公共的行为。可能造成一个结果就是为了维护模型的完成性,大量的对模型行为进行复用,对以前行为进行修改,然后很多流程调用此流程修改复杂。通过贫血模型的方式,稍有不同的两个流程可以通过增加版本的方式实现,但在DDD方式,为了维护模型完整性,修改地方多,不够快,但长远看,模型清楚。
Q&A
领域的核心思想就是将问题域逐级细分,来降低业务理解和系统实现的复杂度。通过领域细分,逐步缩小微服务需要解决的问题域,构建合适的领域模型,而领域模型映射成系统就是微服务了。
DDD在wiki上介绍来看很简单,就是code要和业务领域统一语言。而从系统角度上看,主要目的就是缩小问题域到一个相对容易解决的多个小的问题域然后在解决。
面向对象与DDD的区别?
可以理解为DDD使用了面向对象的思想。在开始接触DDD的过程中很容易感觉,DDD就是面向对象,是,但不仅仅是。DDD更是一种架构的方法论,也是一种划分微服务的方式。
那为什么要划分核心域、通用域和支撑域,主要目的是什么呢?
通用域比如授权、认证,各个企业之间可能区别不大,甚至很多云厂商都能提供的服务。支持域,是一个业务领域的通用的,比如数据字典的查询。这两者严格区分意义不是很大,最重要的是把他们与核心域区别。
核心域可以理解为业务的核心竞争力,同样的业务比如电商,淘宝和京东,虽然京东也有C2C的业务,但是B2C才是京东的核心竞争力,如果真的是资源有限的京东落魄,甚至可以直接干掉这C2C的业务。
再比如主题业务,如果资源有限,比如魅族,其实整个业务都是外包的,在整个Flyme系统看来,显然主题不是个核心域。
总结,区分不同域的属性是通用域、支持域还是核心域,主要是为了资源的合理分配。更高层面上看,这三个领域划分体现了公司的战略方向。
在主题可以看做MIUI系统的一个子域,开始可以认为是一个支撑域,与音乐、应用商店类似,满足特定功能,并且营收为主。但随着业务的发展,后续慢慢变成MIUI中的核心域,不在注重营收更加关注体验,最终与系统UI合并,更加偏重系统的体验。
主题内的核心域、通用域与支撑域?
界限上下文与子域区别?
这两个概念更像是从两个角度去看问题,界限上下文是语义的概念,在同一个界限上下文中有特定的一些概念,而子域是业务角度的划分。
设计领域模型的一般步骤如下:
- 根据需求划分出初步的领域和限界上下文,以及上下文之间的关系
QA:主题的界限上下文?每个界限上下文都是一个微服务?
- 进一步分析每个上下文内部,识别出哪些是实体,哪些是值对象;
-
对实体、值对象进行关联和聚合,划分出聚合的范畴和聚合根; QA:主题中可以以product为聚合根?聚合根有行为?
- 为聚合根设计仓储,并思考实体或值对象的创建方式;
- 在工程中实践领域模型,并在实践中检验模型的合理性,倒推模型中不足的地方并重构。
限界上下文之间的映射关系
- 合作关系(Partnership):两个上下文紧密合作的关系,一荣俱荣,一损俱损。
- 共享内核(Shared Kernel):两个上下文依赖部分共享的模型。
- 客户方-供应方开发(Customer-Supplier Development):上下文之间有组织的上下游依赖。
- 遵奉者(Conformist):下游上下文只能盲目依赖上游上下文。
- 防腐层(Anticorruption Layer):一个上下文通过一些适配和转换与另一个上下文交互。
- 开放主机服务(Open Host Service):定义一种协议来让其他上下文来对本上下文进行访问。
- 发布语言(Published Language):通常与OHS一起使用,用于定义开放主机的协议。
- 大泥球(Big Ball of Mud):混杂在一起的上下文关系,边界不清晰。 另谋他路(SeparateWay):两个完全没有任何联系的上下文。
战术建模——细化上下文
梳理清楚上下文之间的关系后,我们需要从战术层面上剖析上下文内部的组织关系。首先看下DDD中的一些定义。
实体
当一个对象由其标识(而不是属性)区分时,这种对象称为实体(Entity)。
例:最简单的,公安系统的身份信息录入,对于人的模拟,即认为是实体,因为每个人是独一无二的,且其具有唯一标识(如公安系统分发的身份证号码)。
还有,一张票,如果是有座位号的票为实体,没有的像站票就是值对象。
在实践上建议将属性的验证放到实体中。
值对象
当一个对象用于对事务进行描述而没有唯一标识时,它被称作值对象(Value Object)。
例:比如颜色信息,我们只需要知道{“name”:”黑色”,”css”:”#000000”}这样的值信息就能够满足要求了,这避免了我们对标识追踪带来的系统复杂性。
值对象很重要,在习惯了使用数据库的数据建模后,很容易将所有对象看作实体。使用值对象,可以更好地做系统优化、精简设计。
它具有不变性、相等性和可替换性。
PS:不变性,对应开发技巧,可以把构造函数设置为空,并且不提供set方法,只通过工厂来创建。
PS:与分层模型中的VO很像,但分层模型的VO只是对外提供接口使用,而且会根据业务不同删减字段,而这个VO可以在聚合或实体内使用。
在实践中,需要保证值对象创建后就不能被修改,即不允许外部再修改其属性。在不同上下文集成时,会出现模型概念的公用,如商品模型会存在于电商的各个上下文中。在订单上下文中如果你只关注下单时商品信息快照,那么将商品对象视为值对象是很好的选择。
PS:按照是否有唯一标识的标准,这个商品应该是有的。但是在创建订单的时候,需要的只是商品的快照,并不会在调用商品的动作如上下架,需要知道的只是一堆商品的参数,从函数设计上来说只是一堆参数,如果按照面向对象和restfull就是个class,然后从DDD的角度,相对实体,就是VO了。
聚合根
Aggregate(聚合)是一组相关对象的集合,作为一个整体被外界访问,聚合根(Aggregate Root)是这个聚合的根节点。
聚合是一个非常重要的概念,核心领域往往都需要用聚合来表达。其次,聚合在技术上有非常高的价值,可以指导详细设计。
聚合由根实体,值对象和实体组成。
PS:聚合不一定是个场景,如抽奖,在主题的领域内,product可以为一个聚合根
如何创建好的聚合?
边界内的内容具有一致性:在一个事务中只修改一个聚合实例。如果你发现边界内很难接受强一致,不管是出于性能或产品需求的考虑,应该考虑剥离出独立的聚合,采用最终一致的方式。
在一个事务中只修改一个聚合实例
PS:这也要求聚合有完整的业务表达,例如在主题的领域,如商品上线,虽然需要修改很多实体,但是可以通过一个操作聚合的方式来实现。修改很多实体,本来就是不应该暴露出去的知识。
设计小聚合:大部分的聚合都可以只包含根实体,而无需包含其他实体。即使一定要包含,可以考虑将其创建为值对象。
PS:如果一个聚合内包括了多个根实体,非常容易
通过唯一标识来引用其他聚合或实体:当存在对象之间的关联时,建议引用其唯一标识而非引用其整体对象。如果是外部上下文中的实体,引用其唯一标识或将需要的属性构造值对象。 如果聚合创建复杂,推荐使用工厂方法来屏蔽内部复杂的创建逻辑。 聚合内部多个组成对象的关系可以用来指导数据库创建,但不可避免存在一定的抗阻。如聚合中存在List<值对象>,那么在数据库中建立1:N的关联需要将值对象单独建表,此时是有id的,建议不要将该id暴露到资源库外部,对外隐蔽。
领域服务
一些重要的领域行为或操作,可以归类为领域服务。它既不是实体,也不是值对象的范畴。
当我们采用了微服务架构风格,一切领域逻辑的对外暴露均需要通过领域服务来进行。如原本由聚合根暴露的业务逻辑也需要依托于领域服务。
领域事件
领域事件是对领域内发生的活动进行的建模,并不是所有系统都需要领域事件,如果简单的领域,可以使用标准的协议方式进行交互?
DDD工程实现
如代码中所示,一般的工程中包的组织方式为{com.公司名.组织架构.业务.上下文.*},这样的组织结构能够明确的将一个上下文限定在包的内部。
import com.company.team.bussiness.lottery.*;//抽奖上下文
import com.company.team.bussiness.riskcontrol.*;//风控上下文
import com.company.team.bussiness.counter.*;//计数上下文
import com.company.team.bussiness.condition.*;//活动准入上下文
import com.company.team.bussiness.stock.*;//库存上下文
PS:这种加个bussiness的方式,主要是显示的区分的上下文。
对于模块内的组织结构,一般情况下我们是按照领域对象、领域服务、领域资源库、防腐层等组织方式定义的。
import com.company.team.bussiness.lottery.domain.valobj.*;//领域对象-值对象
import com.company.team.bussiness.lottery.domain.entity.*;//领域对象-实体
import com.company.team.bussiness.lottery.domain.aggregate.*;//领域对象-聚合根
import com.company.team.bussiness.lottery.service.*;//领域服务
import com.company.team.bussiness.lottery.repo.*;//领域资源库
import com.company.team.bussiness.lottery.facade.*;//领域防腐层
PS:不是所有的组织都是必须的,如防腐层,只有和外部系统进行交互的时候才需要。