Java Concurrent Map
实现了ConcurrentMap接口的Map在Java中有两个:ConcurrentHashMap, ConcurrentSkipListMap。按照非并发的Map的经验,这两者的区别应该还是在是否有order上,正是的,这ConcurrentSkipListMap可以按照key顺序访问。
Skip list 与 ConcurrentSkipListMap##
参考wiki:
a skip list is a data structure that allows fast search within an ordered sequence of elements.
插入时候会随机先选一个level,下面的图很好的表现了这一动态过程。

这个skip list的结构的get、put也是O(log(n))的操作,那这结构与red-blcak tree比有哪些优势呢?从使用的角度能够推断,同样的对key顺序排放的TreeMap,但是变成支持并发的后,底层结构变成了Skip list,那可以推断,Skip list并发情况在表现比red-black tree要好。
查找与插入从顶层的list开始,其实很像二分查找,所以复杂度为O(log(n)).
上面的图对数值插入有形象的说明,但在作为map的时候,每个元素是有个变长的指针数据的,如下图:
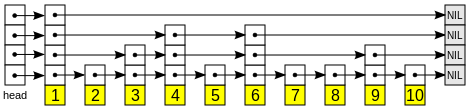
red-black tree的主要问题就是在插入数据的时候可能调整数据的结构,旋转的时候需要锁住很多节点,锁的粒度很大,这对于并发来说是个大忌,而skip list如上图,在插入的时候,只会影响节点相连接的有限个节点,只需要锁住部分节点即可,锁的粒度小,在put的时候还能完成或完成一部分的get操作,这也是skip list的最大的特点。
ConcurrentHashMap
为什么ConcurrentHashMap中的元素不能为null?
ConcurrentHashMap的作者Doug Lea的回答,参考:Handling Null Values in ConcurrentHashMap:
The main reason that nulls aren’t allowed in ConcurrentMaps (ConcurrentHashMaps, ConcurrentSkipListMaps) is that ambiguities that may be just barely tolerable in non-concurrent maps can’t be accommodated. The main one is that if map.get(key) returns null, you can’t detect whether the key explicitly maps to null vs the key isn’t mapped. In a non-concurrent map, you can check this via map.contains(key), but in a concurrent one, the map might have changed between calls.
本来这null元素就有点特殊,map.get(key)如果返回null,其实是有歧义的,可能有null的key也可能没有,需要进行二次判断,map.contains(key),这方式对于不是并发的map还能用,但是对于并发的map,get还contains操作是两个操作,无论先调用哪个,在调用的间隙map中的null的key可能已经变动了。
而且作者对于map中放key为null的方式并不赞同,认为这是在给程序埋雷:
Further digressing: I personally think that allowing nulls in Maps (also Sets) is an open invitation for programs to contain errors that remain undetected until they break at just the wrong time. (Whether to allow nulls even in non-concurrent Maps/Sets is one of the few design issues surrounding Collections that Josh Bloch and I have long disagreed about.)
而且作者给出了解决的方式,定义一个静态的常对象来代替null:
Would it be easier to declare somewhere static final Object NULL = new Object(); and replace all use of nulls in uses of maps with NULL?
JAVA中如何实现
JAVA8中对ConcurrentHashMap进行有优化,而且结构与JAVA8中对HashMap的结构优化的基本一样,JAVA8之前的ConcurrentHashMap是使用的分段锁技术提高并发度,而JAVA8中的ConcurrentHashMap结构与HashMap基本一样,一个大数组加上解决冲突联合使用链表与红黑树的方式,只不过通过锁和volatile等手段支持并发了。
JAVA8之前的ConcurrentHashMap
参考:探索ConcurrentHashMap 高并发性的实现机制
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。
结构如下: 
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。table 是一个由 HashEntry 对象组成的数组。table 数组的每一个数组成员就是散列映射表的一个桶。
在 ConcurrentHashMap中,每一个 Segment 对象都有一个 count 对象来表示本 Segment 中包含的 HashEntry 对象的个数。这样当需要更新计数器时,不用锁定整个 ConcurrentHashMap。
ConcurrentHashMap 在默认并发级别会创建包含 16 个 Segment 对象的数组。每个 Segment 的成员对象 table 包含若干个散列表的桶。每个桶是由 HashEntry 链接起来的一个链表。如果键能均匀散列,每个 Segment 大约守护整个散列表中桶总数的 1/16。
segments的数目也是2的次幂,这与HashMap中分析的大小为什么为2的次幂原因一样。
获取锁时,并不直接使用lock来获取,因为该方法获取锁失败时会挂起(参考可重入锁)。事实上,它使用了自旋锁,如果tryLock获取锁失败,说明锁被其它线程占用,此时通过循环再次以tryLock的方式申请锁。如果在循环过程中该Key所对应的链表头被修改,则重置retry次数。如果retry次数超过一定值,则使用lock方法申请锁。
JAVA8的ConcurrentHashMap
前面提到过,JAVA8的ConcurrentHashMap与JAVA8中的HashMap很像,只不过通过lock-free的方式实现了多线程访问的安全,很多地方使用了CAS操作,不过源码也从2千行到了6千多行。具体的实现方式,待补充。