fastdfs(一)设计解析
概述
fastdfs是淘宝的余庆开发的,github传送门,官网http://www.csource.org/挂掉了,github上没文档说明,大牛就是这么随意。
fastdfs出现的比较早,有很多公司像UC、京东、支付宝、迅雷、酷狗用过,而且比较轻量级,github上下载下来一个155个c文件,包括client和测试代码,一共6w多行,其中关键的storage一个2.8w行,traceker共1.5w行。服务端目前比较稳定。
特点
- 从接口上看像对象存储,返回一个文件的相对路径。
- 只能通过ClientAPI访问,不支持POSIX访问方式。客户端也比较局限,只有linux上的c客户端和java的客户端。其他也有是github上非作者维护的。
- 解决了读写的负载均衡问题。
- 可以配置ngnix直接访问文件,有fastdfs-nginx-module模块,解决了storage之间同步延迟导致访问不到的问题。
- 文件元数据服务器(tracker)为对等的,扩容较简单。
- FastDFS实现了软件方式的RAID,可以使用廉价的IDE硬盘进行存储
- 支持相同内容的文件只保存一份,节约磁盘空间(亮点,但是注意场景,如果不用要关闭此功能)
- FastDFS特别适合大中型网站使用,用来存储资源文件(如:图片、文档、音频、视频等等)
结构
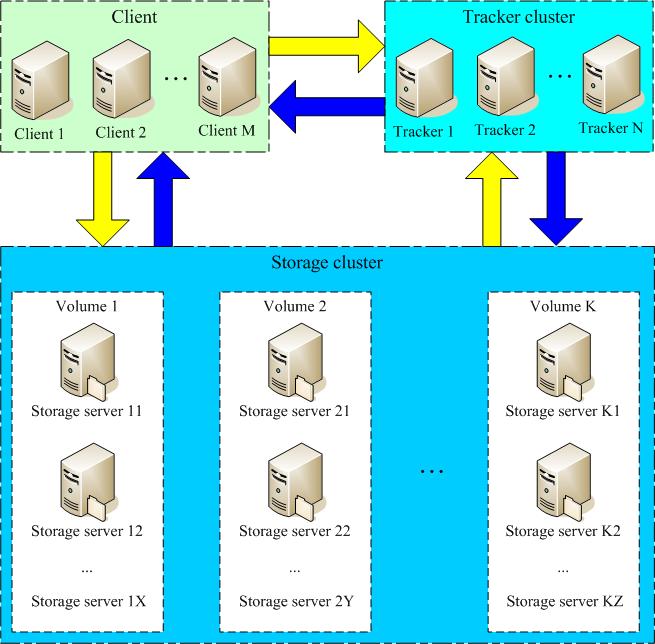
tracker
- 跟踪服务器,主要做调度工作,在访问上起负载均衡的作用。
- 记录storage server的状态,是连接Client和Storage server的枢纽
storage
- 文件和meta data都保存到存储服务器上
- 存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。
group
- 组,也可称为卷,同组内服务器上的文件是完全相同的
- 一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
- 在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。
- 当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
其他
- 文件标识:包括两部分:组名和文件名(包含路径)
- meta data:文件相关属性,键值对(Key Value Pair)方式,如:width=1024,heigth=768
上传下载流程
上传文件交互过程:
- client询问tracker上传到的storage,不需要附加参数;
- tracker返回一台可用的storage;
- client直接和storage通讯完成文件上传。
下载文件交互过程:
- client询问tracker下载文件的storage,参数为文件标识(卷名和文件名);
- tracker返回一台可用的storage;
- client直接和storage通讯完成文件下载。
同步机制
tracker server的配置文件中没有出现storage server,而storage server的配置文件中会列举出所有的tracker server。这就决定了storage server和tracker server之间的连接由storage server主动发起,storage server为每个tracker server启动一个线程进行连接和通讯
不用预先的配置,简化了配置,方便动态的加入。配置信息在新增加的节点上。
tracker server会在内存中保存storage分组及各个组下的storage server,并将连接过自己的storage server及其分组保存到文件中,以便下次重启服务时能直接从本地磁盘中获得storage相关信息。storage server会在内存中记录本组的所有服务器,并将服务器信息记录到文件中。tracker server和storage server之间相互同步storage server列表:
- 如果一个组内增加了新的storage server或者storage server的状态发生了改变,tracker server都会将storage server列表同步给该组内的所有storage server。以新增storage server为例,因为新加入的storage server主动连接tracker server,tracker server发现有新的storage server加入,就会将该组内所有的storage server返回给新加入的storage server,并重新将该组的storage server列表返回给该组内的其他storage server;
- 如果新增加一台tracker server,storage server连接该tracker server,发现该tracker server返回的本组storage server列表比本机记录的要少,就会将该tracker server上没有的storage server同步给该tracker server
有点像Redis cluster进行集群的时候的gossip 协议,节点之间没事就传递一些新的消息。
而且其他方面也像Redis cluster,例如“没有中心节点”,tracker多个是平等的,里面的内容都是一样的,所以也不存在中心节点。不同的是,Redis cluster中的多个master是不同的,管理了不同的范围的slots,是两两之间进行没事的gossip(闲聊交换更新信息)。
而tracker与tracker之间并不直接交换信息(配置文件中也没有在tracker中指定其他的tracker),而是通过storage作为交换信息的中间人,如上面1、2两点所说的。相对来说,简化了信息交换的复杂度。
同一组内的storage server之间是对等的,文件上传、删除等操作可以在任意一台storage server上进行。文件同步只在同组内的storage server之间进行,采用push方式,即源服务器同步给目标服务器。以文件上传为例,假设一个组内有3台storage server A、B和C,文件F上传到服务器B,由B将文件F同步到其余的两台服务器A和C。我们不妨把文件F上传到服务器B的操作为源头操作,在服务器B上的F文件为源头数据;文件F被同步到服务器A和C的操作为备份操作,在A和C上的F文件为备份数据。同步规则总结如下:
- 只在本组内的storage server之间进行同步;
- 源头数据才需要同步,备份数据不需要再次同步,否则就构成环路了;
- 上述第二条规则有个例外,就是新增加一台storage server时,由已有的一台storage server将已有的所有数据(包括源头数据和备份数据)同步给该新增服务器。
这里实现与kafka中的partition的leader有些类似,为了简化设计,kafka的producer和consumer只与leader的partition进行交互,当写入的时候,producer只写入leader的partition,然后slave的partition从leader进行数据的复制。而在写入一特定的storage Server后,上面称为“源数据”其实也可以看成的leader,数据流向一定是从源数据到备份数据,即使再多storage需要备份,也不会有从备份数据到备份数据的操作。这样虽然同步的过程可能比较长,但是简化了过程。
storage server有7个状态,如下:
- FDFS_STORAGE_STATUS_INIT :初始化,尚未得到同步已有数据的源服务器
- FDFS_STORAGE_STATUS_WAIT_SYNC :等待同步,已得到同步已有数据的源服务器
- FDFS_STORAGE_STATUS_SYNCING :同步中
- FDFS_STORAGE_STATUS_DELETED :已删除,该服务器从本组中摘除(注:本状态的功能尚未实现)
- FDFS_STORAGE_STATUS_OFFLINE :离线
- FDFS_STORAGE_STATUS_ONLINE :在线,尚不能提供服务
- FDFS_STORAGE_STATUS_ACTIVE :在线,可以提供服务
当storage server的状态为FDFS_STORAGE_STATUS_ONLINE时,当该storage server向tracker server发起一次heart beat时,tracker server将其状态更改为FDFS_STORAGE_STATUS_ACTIVE。
组内新增加一台storage server A时,由系统自动完成已有数据同步,处理逻辑如下:
- storage server A连接tracker server,tracker server将storage server A的状态设置为FDFS_STORAGE_STATUS_INIT。storage server A询问追加同步的源服务器和追加同步截至时间点,如果该组内只有storage server A或该组内已成功上传的文件数为0,则没有数据需要同步,storage server A就可以提供在线服务,此时tracker将其状态设置为FDFS_STORAGE_STATUS_ONLINE,否则tracker server将其状态设置为FDFS_STORAGE_STATUS_WAIT_SYNC,进入第二步的处理;
- 假设tracker server分配向storage server A同步已有数据的源storage server为B。同组的storage server和tracker server通讯得知新增了storage server A,将启动同步线程,并向tracker server询问向storage server A追加同步的源服务器和截至时间点。storage server B将把截至时间点之前的所有数据同步给storage server A;而其余的storage server从截至时间点之后进行正常同步,只把源头数据同步给storage server A。到了截至时间点之后,storage server B对storage server A的同步将由追加同步切换为正常同步,只同步源头数据;
- storage server B向storage server A同步完所有数据,暂时没有数据要同步时,storage server B请求tracker server将storage server A的状态设置为FDFS_STORAGE_STATUS_ONLINE; 4 当storage server A向tracker server发起heart beat时,tracker server将其状态更改为FDFS_STORAGE_STATUS_ACTIVE。
这里为了提高效率,进行了一次storage到storage的全同步,而后面的同步流程与上面说的一定只从源数据向新增的进行同步。
看到这里,感觉系统实现非常依赖时间戳,不知道是否会有时间戳不一致造成的系统问题。
MyQA
异地备份(灾备)如何支持?
本来是没有这个功能的,但是可以通过配置的方式取巧实现(待测试)。异地备份就是要同步所有的资源文件,而且,尽量是本地操作在本地的tracker和storage上执行,减少网络IO的影响,如果本地的上传文件上传到远端灾备服务器,那么速度可能会很慢。
组网方式是本地一个tracker,一个storage,远端一个tracker一个storage,其中远端的storage与本地的storage在同一个group。然后配置tracker中的# which storage server to upload file的store_server参数,设置本地storage的优先级高,那么本地的写操作都会直接写入storage。远端的storage会慢慢的进行备份。为了保证本地的client连接本地的tracker,那么在本地的client中tracker参数的时候可以只写本地的tracker的ip地址。
负载均衡是如何实现的?
写的时候负载均衡,通过tracker均衡的返回一个storage来实现,在tracker中有相应的配置,字段名字是:store_lookup=2,上传组(卷) 的方式 0:轮询方式 1: 指定组 2:平衡负载(选择最大剩余空间的组(卷)上传),默认为2,轮训方式。貌似也是ngnix的默认方式,简单靠谱。同样,下载的时候也有个参数配置”which storage server to download file“,默认为轮训方式。
优化配置问题
很多与ngnix差不多,感觉比较重要的是storage中的连接是否为长连接,如果文件特别频繁,默认短链接可以考虑改成长连接。
还有日志是否关闭,测试nginx时候发现其实影响不大。
相同文件只存一份的问题需要生成文件摘要,并且对比。其实对性能有损耗的,在没有这场景下要关闭了。
tracker怎么知道storage还没同步完呢?
storage server会定时向tracker server报告同步到其他服务器的状态,tracker server会记录同步到一台storage server的文件的最旧创建时间。如果要下载的文件创建时间比同步到该storage server的文件时间要新,那么就返回上传该文件的源storage server;否则返回当前storage server。 在创建的时候会返回id,请求的时候也是用这个id去请求,这个id包括了文件所在的目录,文件名中是有“时间”参数的。文件名包含存储服务器IP地址、当前时间(Unix时间戳)、文件大小(字节数)和随机数。包含存储服务器的IP地址是为了在寻址的时候快速,直接定位到相应的存储服务上,如果没有,找group(id包含)内的其他storage,并比较storage server的文件的最旧创建时间,如果文件在最旧时间内(已经同步过了),就返回给client。
测试时候发现,两个storage节点storage_stat.dat文件中的total_upload_count与success_upload_count数值并不一致
这两个参数是说当前Storage Server上传的源头数据个数,不是当前Storage Server的真正的文件个数。通过直接进入两个storage的存储文件发现确实存在断线期间的文件,已经自动同步好了。
参考
FastDFS一个高效的分布式文件系统
FastDFS 配置文件详解
官方论坛
FastDFS 5.01 + nginx + cache 集群安装配置手册
FastDFS HOWTO - 同步机制
FastDFS HOWTO – Protocol for V2.04
FastDFS资料整理