MongoDB(三)架构解析
OverView
主要参考MongoDb Architecture 这个文章还有官网。看完后,感觉结构上最大的不同有一下几点:
{kind=link}
- 文档存储么,存储模型有自己的结构
- sharding 策略上,支持两种,ES与Cassandra是Hash的,Hbase是range的,而MongoDB两种都支持,默认是range的,但是Hash策略与上述的不同,Hash完还是按照range进行shard。
- 索引是BTree,而不是B+Tree,BTree适合于内存查找,而B+Tree适合于文件系统上查找,这也要求,MongoDB使用的时候要有足够的内存,否则查找效率会变低。
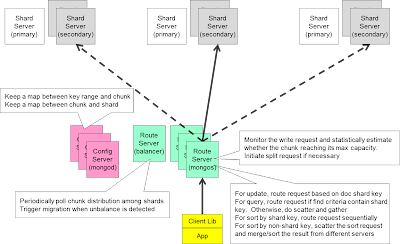
Mongodb架构
Query processing
When there are multiple selection criteria in a query, MongoDb attempts to use one single best index to select a candidate set and then sequentially iterate through them to evaluate other criteria.
如果查询条件组合没有能直接使用的索引,Mongodb也会自己去选择一个存在的,能用的索引对查询进行 优化。
这点与MySQL很像,MySQL也有自己的索引分析的功能。而且在索引很多的时候,分析也会花相当一部分时间。
When there are multiple indexes available for a collection. When handling a query the first time, MongoDb will create multiple execution plans (one for each available index) and let them take turns (within certain number of ticks) to execute until the fastest plan finishes. The result of the fastest executor will be returned and the system remembers the corresponding index used by the fastest executor. Subsequent query will use the remembered index until certain number of updates has happened in the collection, then the system repeats the process to figure out what is the best index at that time.
对上面一段的解释,如何选择出“best index”来优化查询呢?先大概估计下哪几个可以用,然后生成几个候选的plan,在用户查询过程中执行plan,统计下时间,就算出来了。看上去是不怎么高级,没法直接分析出“best index”还要统计分析,原因是因为这“best index”是与文档的数目和结构非常相关的,例如以前使用的一个best索引体积突然膨胀很多,效率可能就会下降,这个时候,就不是best的index了。所以才有“Subsequent query will use the remembered index until certain number of updates has happened in the collection”。
Since only one index will be used, it is important to look at the search or sorting criteria of the query and build additional composite index to match the query better. Maintaining an index is not without cost as index need to be updated when docs are created, deleted and updated, which incurs overhead to the update operations. To maintain an optimal balance, we need to periodically measure the effectiveness of having an index (e.g. the read/write ratio) and delete less efficient indexes.
并不是有多少查询条件,就建立多个个索引的,只要是实时维护的索引,都会有开销的,尤其是在插入的时候需要维护索引。所以,一些复杂的场景下,需要对索引进行周期性的评估,可能有100中查询条件组合,但是不应该有100个索引,而是需要精心的设计出有限少数个如5个索引,满足这100个查询条件的查询,这精心设计出来的5个索引当然也是根据数据的变化可能会变化的,所以说要“periodically measure the effectiveness of having an index (e.g. the read/write ratio) and delete less efficient indexes”,查看一个索引是否有真正的起到作用。
Storage Model
Written in C++, MongoDB uses a memory map file that directly map an on-disk data file to in-memory byte array where data access logic is implemented using pointer arithmetic. Each document collection is stored in one namespace file (which contains metadata information) as well as multiple extent data files (with an exponentially/doubling increasing size).

上面几点关键的
- extend对应一个文档,大小是2次幂大小(有空间浪费)
- 为什么是2的次幂呢?一是对操作系统寻址快,4字节或8字节,二是可以预先批量分配空间,提高读写的吞吐量(自己猜的)
- 有预留的padding空间,用来处理一定范围内文档修改后增大,如果放不下会移动,也有空间浪费
- 索引是BTree?Mysql是B+树,B+树更适合文件系统,为什么Mongodb使用B树?
Data update and Transaction
In RDBMS, “Serializability” is a very fundamental concept about the net effect of concurrently executing work units is equivalent to as if these work units are arrange in some order of sequential execution (one at a time). Therefore, each client can treat as if the DB is exclusively available. The underlying implementation of DB server many use LOCKs or Multi-version to provide the isolation. However, this concept is not available in MongoDb (and many other NOSQL as well)
“可序列化”是并行执行的基础,如果操作不是可序列化的,有两个影响,一是不能通过网络传输,二是不能再服务器进行排队处理,不能排队就变成处理完一个客户端的请求在处理另外一个,这样,很有很多IO的等待,效率大大降低。而且排队处理还有另外一个作用,就是实现数据库的isolation特性,数据库可以根据isolation要求,对于客户端的请求进行合理的安排,从而实现了isolation。
在Mongodb中,没有隔离性,如果修改的时候基于以前的一个值,需要使用findAndModify方式,但这个方式也可能失败,执行完,可以在检查一次。
同样的,没有Transaction的特性,如果想事务地修改两个文档,也有一些其他的方式来实现,可以参考原文。
Replication Model
High availability is achieved in MongoDb via Replica Set, which provides data redundancy across multiple physical servers, including a single primary DB as well as multiple secondary DBs. For data consistency, all modifications (insert / update / deletes) request go to the primary DB where modification is made and asynchronously replicated to the other secondary DBs.

有个Replica Set的概念,与fastdfs的Volume概念很像,只是多了个概念,方式与其他的一样,主从实现,一个组里面有个主的多个从的,写只写入主的,其他的从的异步同步。
For data modification request, the client will send the request to the primary DB, by default the request will be returned once written to the primary, an optional parameter can be specified to indicate a certain number of secondaries need to receive the modification before return so the client can ensure the majority portion of members have got the request. Of course there is a tradeoff between latency and reliability.
这参数,很多都有,但是默认的是只写入一份就返回。而且,在获取更低的latency的时候可能会出现问题,写入的速度一直高于MongoDB自己的同步过程,而写入端不加以截至最后导致资源不足,同样的ES也有这问题。
For query request, by default the client will contact the primary which has the latest updated data. Optionally, the client can specify its willingness to read from any secondaries, and tolerate that the returned data may be outdated. This provide an opportunity to load balance the read request across all secondaries. Notice that in this case, a subsequent read following a write may not seen the update.
由于Mongodb的secondary 是异步的,如果在更新后立刻查询,可能查询不到刚刚更新或插入的值,所以默认的情况下,client是直接连接primary的。
For read-mostly application, reading from any secondaries can be a big performance improvement. To select the fastest secondary DB member to issue query, the client driver periodically pings the members and will favor issuing the query to the one with lowest latency. Notice that read request is issued to only one node, there is no quorum read or read from multiple nodes in MongoDb.
提升性能,不是分片越多越好,大多数情况下,副本越多,提高的效率要比分片多高很多,在ES中,也是如此。如果使用原始的客户端,会与前面提到的选择“best index”一样,客户端会选择一个best的node。还有,在Mongodb中的client不会从多个相同数据的nodes中同时读取然后合并。Hbase会么?
The main purpose of Replica set is to provide data redundancy and also load balance read-request. It doesn’t provide load balancing for write-request since all modification still has to go to the single master.
在一个Replica Set中,没有写的负载均衡。目前为止,知道的不管是分布式的文件系统还是数据库都没有这特性,因为如果能向同一个中写,那同步的时候就太乱了。顶多像Kafka中的,可以把partition多搞出几个来,对应Mongodb,如果写是瓶颈,可以多个几个shard。
Another benefit of replica set is that members can be taken offline on an rotation basis to perform expensive operation such as compaction, indexing or backup, without impacting online clients using the alive members.
可以利用备份服务器轮转地做离线整理(compact)、建立索引、备份,而不需要阻塞在线服务器,但是还是需要在线的主从的切换,应该支持吧。
There is also a special secondary DB called slave delay, which guarantee the data is propagated with a certain time lag with the master. This is used mainly to recover data after accidental deletion of data.
用于进行误删除恢复数据用的。
Sharding Model
To load balance write-request, we can use MongoDb shards. In the sharding setup, a collection can be partitioned (by a partition key) into chunks (which is a key range) and have chunks distributed across multiple shards (each shard will be a replica set). MongoDb sharding effectively provide an unlimited size for data collection, which is important for any big data scenario.

默认的,是按照partition key进行存储到chunks的,官网上的说明的图:

还有一种是hash的,但是hash后的值也有范围的,hash也是按照key的hash值大小进行分chunks的,而不是像redis cluster、es、Java7的ConcurrentHashMap中的,的对分片数取余数决定存在哪里的。这样比较大小的方式有些疑问,上述的结构为什么取余数呢?主要是效率方面考虑,而且取余数的方式分片数目一般是2的次幂个,这样计算的时候直接位操作就可以了,而且扩容也方便。而这比较大小的方式,主要从效率上看,一个值的hash,一是计算的成本,其他分布式系统也有,二是比较的成本,如果生成的hash太长,比较效率也会降低,显然与取余数的方式效率要低(2的次幂时候,只需要从内存中拿出后面的几位就是取余数了)。没有找到MongoDB中的hash使用的方法。用hash后,如下:

这样按照顺序进行划分chunk有什么好处呢?最大的好处就是可以增加Shard的数目,与Hbase一样。第二顺序的方式其实内部进行分裂、迁移都可以有个具体的范围,逻辑处理上也方便些。
分片后,就有了分布查询的问题,与ES的方式特别像,查询可能有分布查询然后合并结果的过程,如果有排序会在下面节点排好序返回。
而且,与Hbase一样,Chunk会自动进行分裂,还会进行均衡,从多的chunk上转移到数据量少的chunk上。
Minimum number of nodes to create a production-ready cluster
Mongodb: 3 nodes: Primary and secondary nodes deployed in a MongoDB replica set
这里3个nodes,应该是物理上的nodes,因为需要考虑脑裂问题。
图是官网上的: 
MongoDB Limits and Thresholds
这部分直接参考官网,列出几个关键的数据:
The maximum BSON document size is 16 megabytes. MongoDB supports no more than 100 levels of nesting for BSON documents. A single collection can have no more than 64 indexes. There can be no more than 31 fields in a compound index.
If you specify a maximum number of documents for a capped collection using the max parameter to create, the limit must be less than 232 documents. If you do not specify a maximum number of documents when creating a capped collection, there is no limit on the number of documents.
The MMAPv1 storage engine limits each database to no more than 16000 data files. This means that a single MMAPv1 database has a maximum size of 32TB.
存储引擎
参考MongoDB 存储引擎 mongorocks 原理解析
Q & A
- Does a sharded only keep its own BTree in memory…?
Yes, each shard manages its own indexes.
每个shard只在内存中保存自己的index,而不是所有的,这其实无关紧要,因为“If you do a query using the shard key, it will be routed directly to the correct server(s).”
- The word on the street is that MongoDB gets slow if you can’t keep the indexes you’re using in memory.
You can actually expect worse when using sharding and secondary indexes. The key problem is that the router process (mongos) knows nothing about data in secondary indexes.
If you do a query using the shard key, it will be routed directly to the correct server(s). In most cases, this levels out the workload. So 100 queries can be spread across 100 servers and each server only answers 1 query.
However, if you do a query using the secondary key, that query has to go to every server. So 100 queries to the router will result 10,000 queries across 100 servers or 100 queries per server. As you add more servers, these “non-shardkey” queries become less and less efficient. The workload does not become more balanced.
对这句“So 100 queries to the router will result 10,000 queries across 100 servers or 100 queries per server.”分析下,如果有100个server,因为每个servers有一个shard,而每个shard只维护自己拥有数据的BTree,shard只能按照一种策略进行,默认是_id,如果查询不是按照id来的,假设有个userid,那么查询的时候也不知道去哪个分片查询,而是发送给所有的shard,shard上找userid对应的BTree,这样,1次查询,在集群中就会触发分片次数次的查询100次,100次,就是100次了。
其实这也没啥,在ES上也是这样的,但这也从侧面说明了分片过多会导致的问题。
Hbase在建立二级索引的时候,与MongoDB上只管自己数据的BTree一样,二级索引的磁盘上位置最好与region是在一个地方。而且Hbase的二级索引,应该也是有这问题,需要给所有的RegionServer,然后进行汇总。
参考:
MongoDb Architecture
MongoDb Architecture(翻译)
MongoDB Limits and Thresholds